Note
Go to the end to download the full example code.
Training an FNO on Darcy-Flow
In this example, we demonstrate how to use the small Darcy-Flow example we ship with the package to train a Fourier Neural Operator.
Note that this dataset is much smaller than one we would use in practice. The small Darcy-flow is an example built to be trained on a CPU in a few seconds, whereas normally we would train on one or multiple GPUs.
import torch
import matplotlib.pyplot as plt
import sys
from neuralop.models import FNO
from neuralop import Trainer
from neuralop.training import AdamW
from neuralop.data.datasets import load_darcy_flow_small
from neuralop.utils import count_model_params
from neuralop import LpLoss, H1Loss
device = 'cpu'
Let’s load the small Darcy-flow dataset.
train_loader, test_loaders, data_processor = load_darcy_flow_small(
n_train=1000, batch_size=32,
test_resolutions=[16, 32], n_tests=[100, 50],
test_batch_sizes=[32, 32],
)
data_processor = data_processor.to(device)
/home/runner/work/neuraloperator/neuraloperator/neuralop/data/datasets/pt_dataset.py:93: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
data = torch.load(
Loading test db for resolution 16 with 100 samples
/home/runner/work/neuraloperator/neuraloperator/neuralop/data/datasets/pt_dataset.py:172: FutureWarning: You are using `torch.load` with `weights_only=False` (the current default value), which uses the default pickle module implicitly. It is possible to construct malicious pickle data which will execute arbitrary code during unpickling (See https://github.com/pytorch/pytorch/blob/main/SECURITY.md#untrusted-models for more details). In a future release, the default value for `weights_only` will be flipped to `True`. This limits the functions that could be executed during unpickling. Arbitrary objects will no longer be allowed to be loaded via this mode unless they are explicitly allowlisted by the user via `torch.serialization.add_safe_globals`. We recommend you start setting `weights_only=True` for any use case where you don't have full control of the loaded file. Please open an issue on GitHub for any issues related to this experimental feature.
data = torch.load(Path(root_dir).joinpath(f"{dataset_name}_test_{res}.pt").as_posix())
Loading test db for resolution 32 with 50 samples
We create a simple FNO model
model = FNO(n_modes=(16, 16),
in_channels=1,
out_channels=1,
hidden_channels=32,
projection_channel_ratio=2)
model = model.to(device)
n_params = count_model_params(model)
print(f'\nOur model has {n_params} parameters.')
sys.stdout.flush()
Our model has 1192801 parameters.
Training setup
Create the optimizer
optimizer = AdamW(model.parameters(),
lr=8e-3,
weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=30)
Then create the losses
l2loss = LpLoss(d=2, p=2)
h1loss = H1Loss(d=2)
train_loss = h1loss
eval_losses={'h1': h1loss, 'l2': l2loss}
Training the model
print('\n### MODEL ###\n', model)
print('\n### OPTIMIZER ###\n', optimizer)
print('\n### SCHEDULER ###\n', scheduler)
print('\n### LOSSES ###')
print(f'\n * Train: {train_loss}')
print(f'\n * Test: {eval_losses}')
sys.stdout.flush()
### MODEL ###
FNO(
(positional_embedding): GridEmbeddingND()
(fno_blocks): FNOBlocks(
(convs): ModuleList(
(0-3): 4 x SpectralConv(
(weight): DenseTensor(shape=torch.Size([32, 32, 16, 9]), rank=None)
)
)
(fno_skips): ModuleList(
(0-3): 4 x Flattened1dConv(
(conv): Conv1d(32, 32, kernel_size=(1,), stride=(1,), bias=False)
)
)
(channel_mlp): ModuleList(
(0-3): 4 x ChannelMLP(
(fcs): ModuleList(
(0): Conv1d(32, 16, kernel_size=(1,), stride=(1,))
(1): Conv1d(16, 32, kernel_size=(1,), stride=(1,))
)
)
)
(channel_mlp_skips): ModuleList(
(0-3): 4 x SoftGating()
)
)
(lifting): ChannelMLP(
(fcs): ModuleList(
(0): Conv1d(3, 64, kernel_size=(1,), stride=(1,))
(1): Conv1d(64, 32, kernel_size=(1,), stride=(1,))
)
)
(projection): ChannelMLP(
(fcs): ModuleList(
(0): Conv1d(32, 64, kernel_size=(1,), stride=(1,))
(1): Conv1d(64, 1, kernel_size=(1,), stride=(1,))
)
)
)
### OPTIMIZER ###
AdamW (
Parameter Group 0
betas: (0.9, 0.999)
correct_bias: True
eps: 1e-06
initial_lr: 0.008
lr: 0.008
weight_decay: 0.0001
)
### SCHEDULER ###
<torch.optim.lr_scheduler.CosineAnnealingLR object at 0x7fb4d55e2710>
### LOSSES ###
* Train: <neuralop.losses.data_losses.H1Loss object at 0x7fb4d55e3250>
* Test: {'h1': <neuralop.losses.data_losses.H1Loss object at 0x7fb4d55e3250>, 'l2': <neuralop.losses.data_losses.LpLoss object at 0x7fb4d55e2350>}
Create the trainer:
trainer = Trainer(model=model, n_epochs=20,
device=device,
data_processor=data_processor,
wandb_log=False,
eval_interval=3,
use_distributed=False,
verbose=True)
Then train the model on our small Darcy-Flow dataset:
trainer.train(train_loader=train_loader,
test_loaders=test_loaders,
optimizer=optimizer,
scheduler=scheduler,
regularizer=False,
training_loss=train_loss,
eval_losses=eval_losses)
Training on 1000 samples
Testing on [50, 50] samples on resolutions [16, 32].
Raw outputs of shape torch.Size([32, 1, 16, 16])
[0] time=2.56, avg_loss=0.6956, train_err=21.7383
Eval: 16_h1=0.4298, 16_l2=0.3487, 32_h1=0.5847, 32_l2=0.3542
[3] time=2.53, avg_loss=0.2103, train_err=6.5705
Eval: 16_h1=0.2030, 16_l2=0.1384, 32_h1=0.5075, 32_l2=0.1774
[6] time=2.54, avg_loss=0.1911, train_err=5.9721
Eval: 16_h1=0.2099, 16_l2=0.1374, 32_h1=0.4907, 32_l2=0.1783
[9] time=2.53, avg_loss=0.1410, train_err=4.4073
Eval: 16_h1=0.2052, 16_l2=0.1201, 32_h1=0.5268, 32_l2=0.1615
[12] time=2.53, avg_loss=0.1422, train_err=4.4434
Eval: 16_h1=0.2131, 16_l2=0.1285, 32_h1=0.5413, 32_l2=0.1741
[15] time=2.57, avg_loss=0.1198, train_err=3.7424
Eval: 16_h1=0.1984, 16_l2=0.1137, 32_h1=0.5255, 32_l2=0.1569
[18] time=2.52, avg_loss=0.1104, train_err=3.4502
Eval: 16_h1=0.2039, 16_l2=0.1195, 32_h1=0.5062, 32_l2=0.1603
{'train_err': 2.9605126455426216, 'avg_loss': 0.0947364046573639, 'avg_lasso_loss': None, 'epoch_train_time': 2.5225613149999617}
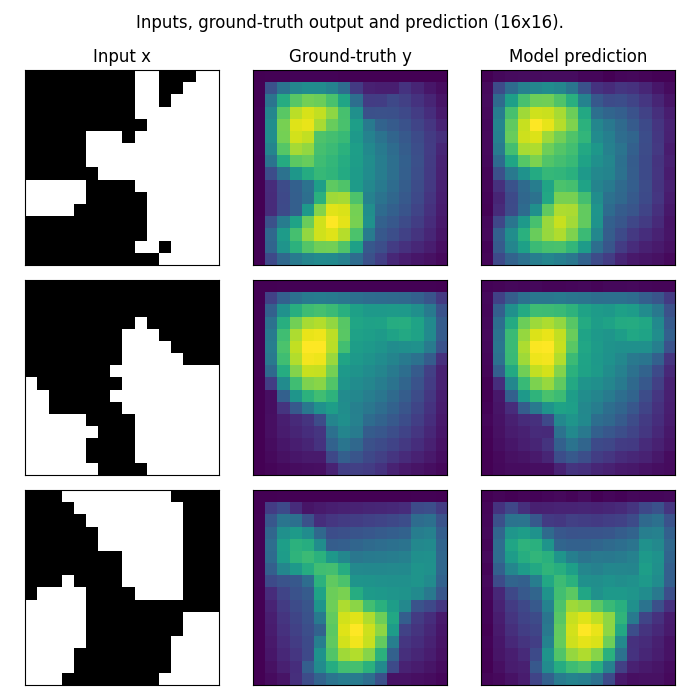
Visualizing predictions
Let’s take a look at what our model’s predicted outputs look like. Again note that in this example, we train on a very small resolution for a very small number of epochs. In practice, we would train at a larger resolution, on many more samples.
test_samples = test_loaders[16].dataset
fig = plt.figure(figsize=(7, 7))
for index in range(3):
data = test_samples[index]
data = data_processor.preprocess(data, batched=False)
# Input x
x = data['x']
# Ground-truth
y = data['y']
# Model prediction
out = model(x.unsqueeze(0))
ax = fig.add_subplot(3, 3, index*3 + 1)
ax.imshow(x[0], cmap='gray')
if index == 0:
ax.set_title('Input x')
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index*3 + 2)
ax.imshow(y.squeeze())
if index == 0:
ax.set_title('Ground-truth y')
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index*3 + 3)
ax.imshow(out.squeeze().detach().numpy())
if index == 0:
ax.set_title('Model prediction')
plt.xticks([], [])
plt.yticks([], [])
fig.suptitle('Inputs, ground-truth output and prediction (16x16).', y=0.98)
plt.tight_layout()
fig.show()
Zero-shot super-evaluation
In addition to training and making predictions on the same input size, the FNO’s invariance to the discretization of input data means we can natively make predictions on higher-resolution inputs and get higher-resolution outputs.
test_samples = test_loaders[32].dataset
fig = plt.figure(figsize=(7, 7))
for index in range(3):
data = test_samples[index]
data = data_processor.preprocess(data, batched=False)
# Input x
x = data['x']
# Ground-truth
y = data['y']
# Model prediction
out = model(x.unsqueeze(0))
ax = fig.add_subplot(3, 3, index*3 + 1)
ax.imshow(x[0], cmap='gray')
if index == 0:
ax.set_title('Input x')
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index*3 + 2)
ax.imshow(y.squeeze())
if index == 0:
ax.set_title('Ground-truth y')
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index*3 + 3)
ax.imshow(out.squeeze().detach().numpy())
if index == 0:
ax.set_title('Model prediction')
plt.xticks([], [])
plt.yticks([], [])
fig.suptitle('Inputs, ground-truth output and prediction (32x32).', y=0.98)
plt.tight_layout()
fig.show()
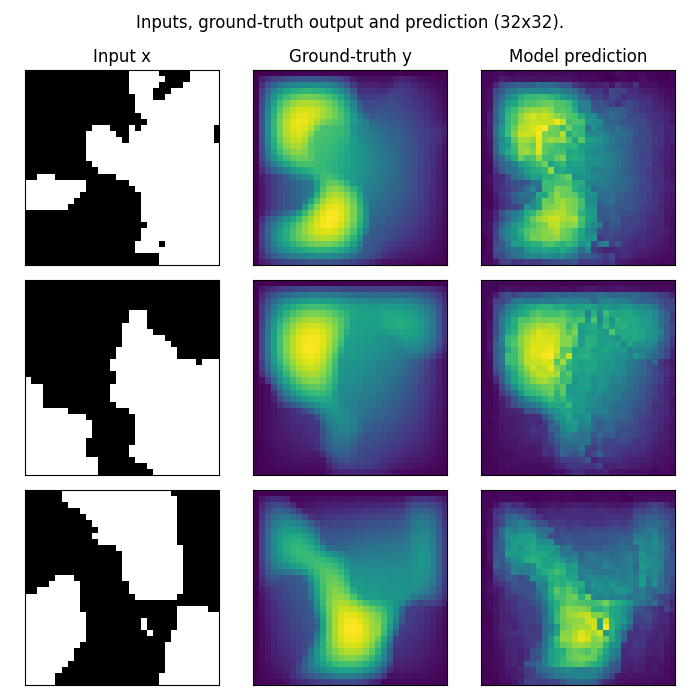
We only trained the model on data at a resolution of 16x16, and with no modifications or special prompting, we were able to perform inference on higher-resolution input data and get higher-resolution predictions! In practice, we often want to evaluate neural operators at multiple resolutions to track a model’s zero-shot super-evaluation performance throughout training. That’s why many of our datasets, including the small Darcy-flow we showcased, are parameterized with a list of test_resolutions to choose from.
However, as you can see, these predictions are noisier than we would expect for a model evaluated at the same resolution at which it was trained. Leveraging the FNO’s discretization-invariance, there are other ways to scale the outputs of the FNO to train a true super-resolution capability.
Total running time of the script: (0 minutes 51.971 seconds)