Note
Go to the end to download the full example code
Training a neural operator on Darcy-Flow - Author Robert Joseph George
In this example, we demonstrate how to use the small Darcy-Flow example we ship with the package on Incremental FNO and Incremental Resolution
import torch
import matplotlib.pyplot as plt
import sys
from neuralop.models import FNO
from neuralop import Trainer
from neuralop.datasets import load_darcy_flow_small
from neuralop.utils import count_model_params
from neuralop.training.callbacks import IncrementalCallback
from neuralop.datasets import data_transforms
from neuralop import LpLoss, H1Loss
Loading the Darcy flow dataset
train_loader, test_loaders, output_encoder = load_darcy_flow_small(
n_train=100,
batch_size=16,
test_resolutions=[16, 32],
n_tests=[100, 50],
test_batch_sizes=[32, 32],
)
Loading test db at resolution 32 with 50 samples and batch-size=32
Choose device
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
Set up the incremental FNO model We start with 2 modes in each dimension We choose to update the modes by the incremental gradient explained algorithm
incremental = True
if incremental:
starting_modes = (2, 2)
else:
starting_modes = (16, 16)
set up model
model = FNO(
max_n_modes=(16, 16),
n_modes=starting_modes,
hidden_channels=32,
in_channels=1,
out_channels=1,
)
model = model.to(device)
n_params = count_model_params(model)
Set up the optimizer and scheduler
optimizer = torch.optim.Adam(model.parameters(), lr=8e-3, weight_decay=1e-4)
scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max=30)
# If one wants to use Incremental Resolution, one should use the IncrementalDataProcessor - When passed to the trainer, the trainer will automatically update the resolution
# Incremental_resolution : bool, default is False
# if True, increase the resolution of the input incrementally
# uses the incremental_res_gap parameter
# uses the subsampling_rates parameter - a list of resolutions to use
# uses the dataset_indices parameter - a list of indices of the dataset to slice to regularize the input resolution
# uses the dataset_resolution parameter - the resolution of the input
# uses the epoch_gap parameter - the number of epochs to wait before increasing the resolution
# uses the verbose parameter - if True, print the resolution and the number of modes
data_transform = data_transforms.IncrementalDataProcessor(
in_normalizer=None,
out_normalizer=None,
positional_encoding=None,
device=device,
subsampling_rates=[2, 1],
dataset_resolution=16,
dataset_indices=[2, 3],
epoch_gap=10,
verbose=True,
)
data_transform = data_transform.to(device)
Original Incre Res: change index to 0
Original Incre Res: change sub to 2
Original Incre Res: change res to 8
Set up the losses
l2loss = LpLoss(d=2, p=2)
h1loss = H1Loss(d=2)
train_loss = h1loss
eval_losses = {"h1": h1loss, "l2": l2loss}
print("\n### N PARAMS ###\n", n_params)
print("\n### OPTIMIZER ###\n", optimizer)
print("\n### SCHEDULER ###\n", scheduler)
print("\n### LOSSES ###")
print("\n### INCREMENTAL RESOLUTION + GRADIENT EXPLAINED ###")
print(f"\n * Train: {train_loss}")
print(f"\n * Test: {eval_losses}")
sys.stdout.flush()
### N PARAMS ###
2118817
### OPTIMIZER ###
Adam (
Parameter Group 0
amsgrad: False
betas: (0.9, 0.999)
capturable: False
differentiable: False
eps: 1e-08
foreach: None
fused: None
initial_lr: 0.008
lr: 0.008
maximize: False
weight_decay: 0.0001
)
### SCHEDULER ###
<torch.optim.lr_scheduler.CosineAnnealingLR object at 0x7f1cd634d2e0>
### LOSSES ###
### INCREMENTAL RESOLUTION + GRADIENT EXPLAINED ###
* Train: <neuralop.losses.data_losses.H1Loss object at 0x7f1cd62d39a0>
* Test: {'h1': <neuralop.losses.data_losses.H1Loss object at 0x7f1cd62d39a0>, 'l2': <neuralop.losses.data_losses.LpLoss object at 0x7f1cfbed64c0>}
Set up the IncrementalCallback other options include setting incremental_loss_gap = True If one wants to use incremental resolution set it to True In this example we only update the modes and not the resolution When using the incremental resolution one should keep in mind that the numnber of modes initially set should be strictly less than the resolution Again these are the various paramaters for the various incremental settings incremental_grad : bool, default is False
if True, use the base incremental algorithm which is based on gradient variance uses the incremental_grad_eps parameter - set the threshold for gradient variance uses the incremental_buffer paramater - sets the number of buffer modes to calculate the gradient variance uses the incremental_max_iter parameter - sets the initial number of iterations uses the incremental_grad_max_iter parameter - sets the maximum number of iterations to accumulate the gradients
- incremental_loss_gapbool, default is False
if True, use the incremental algorithm based on loss gap uses the incremental_loss_eps parameter
One can use multiple Callbacks as well
callbacks = [
IncrementalCallback(
incremental_loss_gap=False,
incremental_grad=True,
incremental_grad_eps=0.9999,
incremental_loss_eps = 0.001,
incremental_buffer=5,
incremental_max_iter=1,
incremental_grad_max_iter=2,
)
]
# Finally pass all of these to the Trainer
trainer = Trainer(
model=model,
n_epochs=20,
data_processor=data_transform,
callbacks=callbacks,
device=device,
verbose=True,
)
using standard method to load data to device.
using standard method to compute loss.
self.override_load_to_device=False
self.overrides_loss=False
Train the model
trainer.train(
train_loader,
test_loaders,
optimizer,
scheduler,
regularizer=False,
training_loss=train_loss,
eval_losses=eval_losses,
)
Training on 100 samples
Testing on [50, 50] samples on resolutions [16, 32].
Raw outputs of size out.shape=torch.Size([16, 1, 8, 8])
[0] time=0.13, avg_loss=0.8211, train_err=11.7296, 16_h1=0.7480, 16_l2=0.5862, 32_h1=0.7621, 32_l2=0.5737
Currently the model is using incremental_n_modes = [2, 2]
[1] time=0.12, avg_loss=0.7347, train_err=10.4951, 16_h1=0.7281, 16_l2=0.5719, 32_h1=0.7540, 32_l2=0.5608
Currently the model is using incremental_n_modes = [2, 2]
[2] time=0.13, avg_loss=0.7136, train_err=10.1937, 16_h1=0.7130, 16_l2=0.5539, 32_h1=0.7425, 32_l2=0.5420
Currently the model is using incremental_n_modes = [3, 2]
[3] time=0.13, avg_loss=0.7364, train_err=10.5200, 16_h1=0.7717, 16_l2=0.6129, 32_h1=0.7877, 32_l2=0.6047
Currently the model is using incremental_n_modes = [3, 2]
[4] time=0.13, avg_loss=0.7374, train_err=10.5348, 16_h1=0.7355, 16_l2=0.5831, 32_h1=0.7632, 32_l2=0.5739
Currently the model is using incremental_n_modes = [3, 2]
[5] time=0.13, avg_loss=0.7139, train_err=10.1984, 16_h1=0.7260, 16_l2=0.5667, 32_h1=0.7564, 32_l2=0.5557
Currently the model is using incremental_n_modes = [4, 3]
[6] time=0.14, avg_loss=0.7017, train_err=10.0248, 16_h1=0.7278, 16_l2=0.5762, 32_h1=0.7471, 32_l2=0.5678
Currently the model is using incremental_n_modes = [4, 3]
[7] time=0.14, avg_loss=0.7082, train_err=10.1179, 16_h1=0.7770, 16_l2=0.6087, 32_h1=0.8044, 32_l2=0.5931
Currently the model is using incremental_n_modes = [4, 3]
[8] time=0.14, avg_loss=0.6999, train_err=9.9988, 16_h1=0.6970, 16_l2=0.5474, 32_h1=0.7220, 32_l2=0.5381
Currently the model is using incremental_n_modes = [5, 3]
[9] time=0.15, avg_loss=0.6500, train_err=9.2861, 16_h1=0.7129, 16_l2=0.5535, 32_h1=0.7449, 32_l2=0.5409
Currently the model is using incremental_n_modes = [5, 3]
Incre Res Update: change index to 1
Incre Res Update: change sub to 1
Incre Res Update: change res to 16
[10] time=0.22, avg_loss=0.6308, train_err=9.0117, 16_h1=0.6834, 16_l2=0.5390, 32_h1=0.6974, 32_l2=0.5196
Currently the model is using incremental_n_modes = [5, 3]
[11] time=0.21, avg_loss=0.6035, train_err=8.6221, 16_h1=0.6983, 16_l2=0.5524, 32_h1=0.7139, 32_l2=0.5383
Currently the model is using incremental_n_modes = [6, 4]
[12] time=0.23, avg_loss=0.5728, train_err=8.1834, 16_h1=0.7086, 16_l2=0.5551, 32_h1=0.7218, 32_l2=0.5382
Currently the model is using incremental_n_modes = [6, 4]
[13] time=0.23, avg_loss=0.5435, train_err=7.7644, 16_h1=0.7011, 16_l2=0.5599, 32_h1=0.7118, 32_l2=0.5452
Currently the model is using incremental_n_modes = [6, 4]
[14] time=0.23, avg_loss=0.4986, train_err=7.1235, 16_h1=0.7174, 16_l2=0.5682, 32_h1=0.7241, 32_l2=0.5493
Currently the model is using incremental_n_modes = [7, 4]
[15] time=0.23, avg_loss=0.4516, train_err=6.4507, 16_h1=0.6799, 16_l2=0.5357, 32_h1=0.6936, 32_l2=0.5225
Currently the model is using incremental_n_modes = [7, 4]
[16] time=0.24, avg_loss=0.4067, train_err=5.8103, 16_h1=0.7179, 16_l2=0.5686, 32_h1=0.7232, 32_l2=0.5507
Currently the model is using incremental_n_modes = [7, 4]
[17] time=0.23, avg_loss=0.3629, train_err=5.1848, 16_h1=0.6999, 16_l2=0.5490, 32_h1=0.7134, 32_l2=0.5342
Currently the model is using incremental_n_modes = [8, 5]
[18] time=0.24, avg_loss=0.3323, train_err=4.7469, 16_h1=0.7163, 16_l2=0.5630, 32_h1=0.7246, 32_l2=0.5479
Currently the model is using incremental_n_modes = [8, 5]
[19] time=0.23, avg_loss=0.3028, train_err=4.3255, 16_h1=0.7108, 16_l2=0.5589, 32_h1=0.7230, 32_l2=0.5450
Currently the model is using incremental_n_modes = [8, 5]
{'32_h1': 0.722979679107666, '32_l2': 0.5449663162231445}
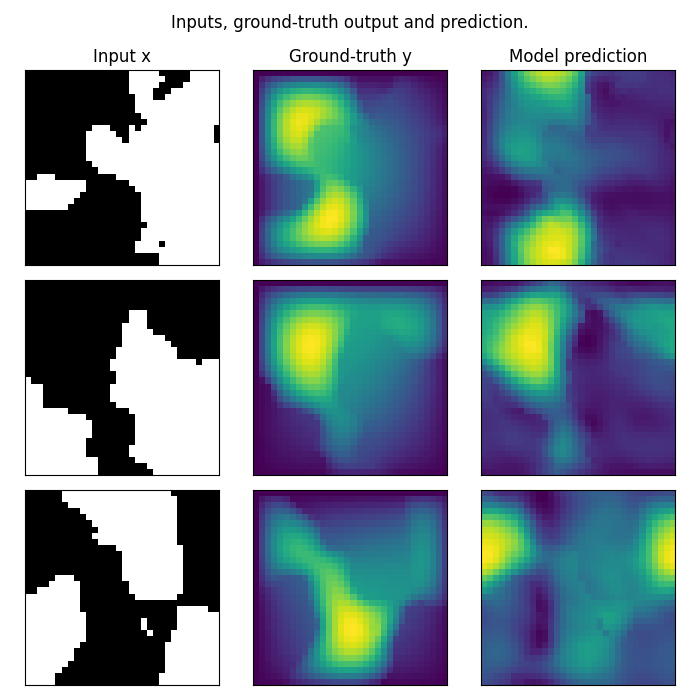
Plot the prediction, and compare with the ground-truth Note that we trained on a very small resolution for a very small number of epochs In practice, we would train at larger resolution, on many more samples.
However, for practicity, we created a minimal example that i) fits in just a few Mb of memory ii) can be trained quickly on CPU
In practice we would train a Neural Operator on one or multiple GPUs
test_samples = test_loaders[32].dataset
fig = plt.figure(figsize=(7, 7))
for index in range(3):
data = test_samples[index]
# Input x
x = data["x"].to(device)
# Ground-truth
y = data["y"].to(device)
# Model prediction
out = model(x.unsqueeze(0))
ax = fig.add_subplot(3, 3, index * 3 + 1)
x = x.cpu().squeeze().detach().numpy()
y = y.cpu().squeeze().detach().numpy()
ax.imshow(x, cmap="gray")
if index == 0:
ax.set_title("Input x")
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index * 3 + 2)
ax.imshow(y.squeeze())
if index == 0:
ax.set_title("Ground-truth y")
plt.xticks([], [])
plt.yticks([], [])
ax = fig.add_subplot(3, 3, index * 3 + 3)
ax.imshow(out.cpu().squeeze().detach().numpy())
if index == 0:
ax.set_title("Model prediction")
plt.xticks([], [])
plt.yticks([], [])
fig.suptitle("Inputs, ground-truth output and prediction.", y=0.98)
plt.tight_layout()
fig.show()
Total running time of the script: (0 minutes 6.446 seconds)